History: Camillo's Mestrado Thesis
[Abstract] [Results] [Publications] [Source Code] [History] [References]
Advances in GPU architecture and its rapidly evolving towards general purpose GPU (GPGPU) make a series of applications adopt a GPGPU and graphics computing interoperability approach in which the first is used for heavy computations and the second for 3D graphics rendering.
GPGPU APIs, like CUDA, explicitly expose several hardware features, such as shared memory and thread synchronization mechanisms.
This is particularly attractive to applications with random (non-coalesced) memory accesses, as it allows developers to write more efficient code for handling these accesses.
At the same time, several studies show that, for graphics applications or programs that require graphical visualization of their results, an OpenGL implementation has better performance than implementations based on OpenGL and CUDA interoperation.
In this dissertation we draw a comparison of the use of OpenGL and CUDA for random (non-coalesced) accesses to the 1-ring neighborhood of a vertex.
We study two examples of this problem: curvature tensor estimation and N-body simulation.
In both cases we implement the same algorithm with the CUDA and OpenGL APIs. We analyzed the hardware features exposed by each API and their equivalence, including non-graphics usage of the OpenGL pipeline.
Comparative timing analysis is provided to validate our results.
We believe that our study provides a better understanding of the graphics features that are useful for closing the performance gap between OpenGL and CUDA based implementations, and open new perspectives on implementing, solely with the OpenGL, graphics applications that require both intense but pre-specified memory access and 3D graphics rendering.
Back to top
We compared different implementations, using different hardware features and optimization techniques, for each of the two problems running in a few different GPU architectures from NVidia.
The table below shows the configurations of the computers used for our experiments.
Computer's name
|
Processor
|
RAM
|
GPU
|
# CUDA cores
|
Fermi
|
Intel i5
|
8 GB
|
NVidia GeForce 540M 1 GB VRAM
|
96
|
Kepler
|
Intel i7
|
16 GB
|
NVidia GeForce GTX Titan 6 GB VRAM
|
2688
|
Maxwell
|
Intel Xeon
|
16 GB
|
NVidia GeForce GTX Titan X 12 GB VRAM
|
3072
|
Pascal
|
Intel i7
|
16 GB
|
NVidia GeForce GTX 1080 8 GB VRAM
|
2560
|
For the curvature tensor estimation problem we implemented three different solutions based on Rusinkiewicz[4] CPU algorithm.
The first was a translation of the DirectX+HLSL algorithm of Griffin et al.[1] to OpenGL+GLSL.
The next one was a OpenGL/CUDA inter-operation implementation that used shared memory to lessen the amount of non-coalesced accesses to the GPUs main memory.
And the last one was an OpenGL only implementation that used tessellation shaders.
The results obtained, detailed in the graphs below, corroborate earlier studies, including Griffin et al.[1], which show that implementations using only OpenGL have better performance than OpenGL/CUDA inter-operation.
Griffin et al.[1] algorithm that uses geometry shader for implicitly accessing the 1-ring neighborhood and the blending for the summation, outperforms the others throughout.
Curvature Tensor Estimation Results
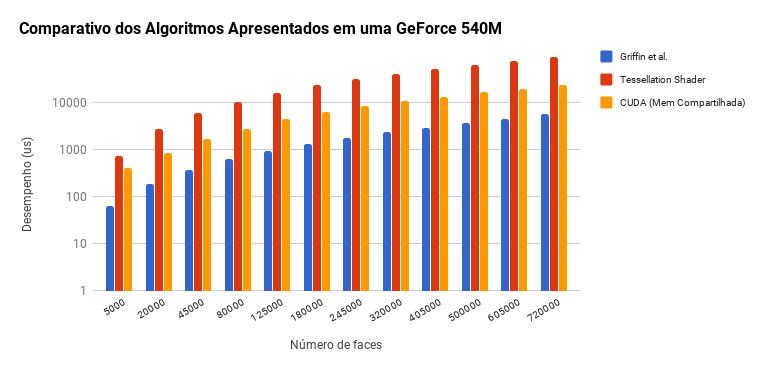
Algorithms comparison in Fermi
|
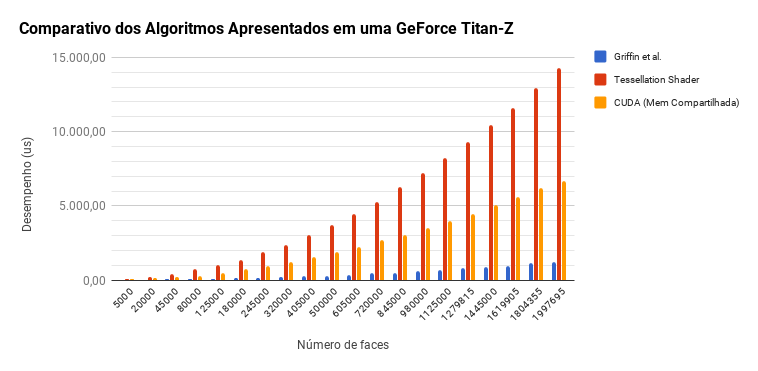
Algorithms comparison in Kepler
|
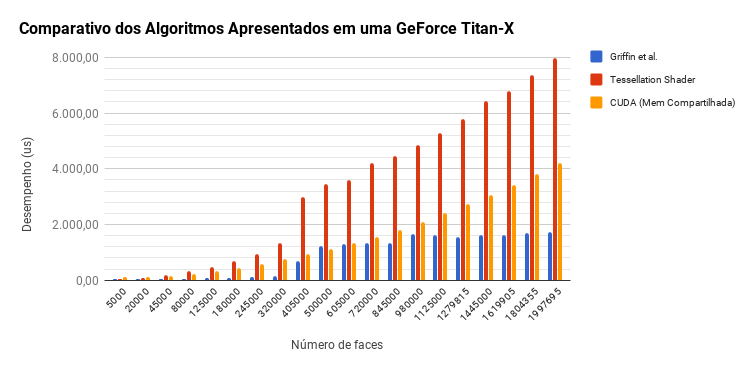
Algorithms comparison in Maxwell
|
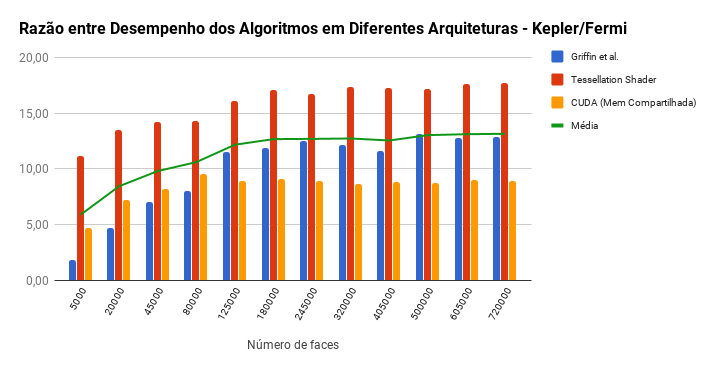
Comparison of speedups for each algorithm between Fermi and Kepler
|
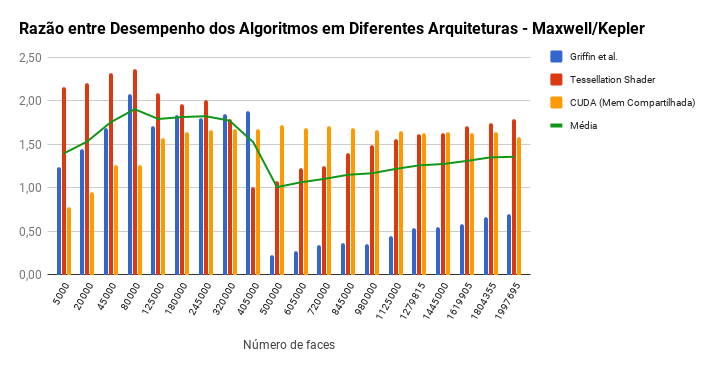
Comparison of speedups for each algorithm between Kepler and Maxwell
|
For the n-body simulation we used the implementation from Nyland et al.[3] as a base and changed the interaction computation step from CUDA (in the original), to three new implementations using only OpenGL's graphic pipeline: one using geometry shader, one using tessellation shader and the last one using tessellation shaders with instanced rendering.
The results (see graphs below) show how the different features available in the graphics pipeline affects the performance of the n-body simulation.
Our novel use of tessellation shader to access the shared memory via patch primitive and instanced rendering to maximize the memory bandwidth by grouping nearby accesses into the same instance achieves performance comparable to CUDA.
It is interesting to notice that OpenGL has a limit on the patch size (which, in this case, corresponds to the block size in CUDA).
This limitation explains the dip in tessellation+instancing performance after a certain number of bodies, but if we set the block size to 32 in CUDA (right most graph), the performance is almost identical.
n-body Simulation Results
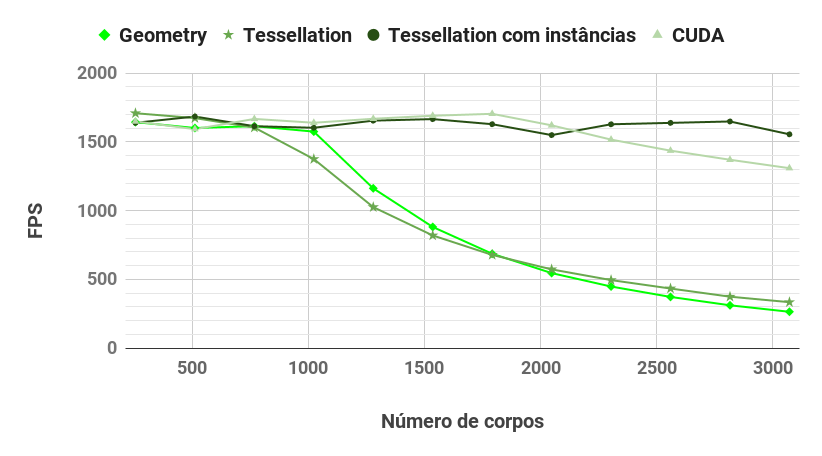
All four algorithms comparison in Kepler
|
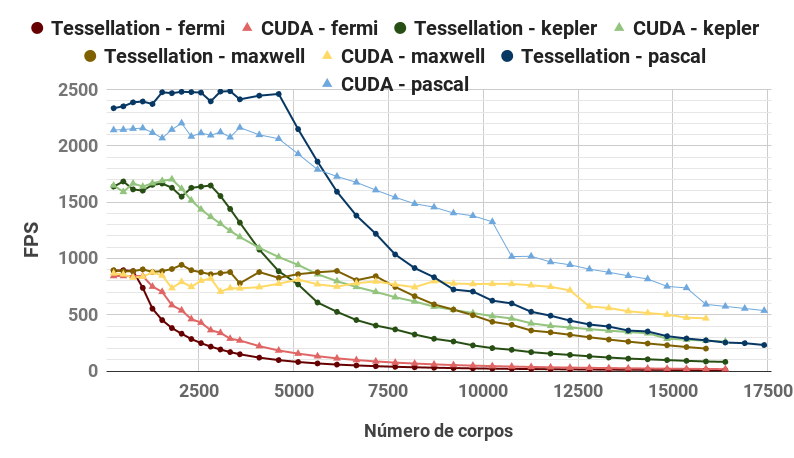
CUDA and tessellation+instancing comparison in all four GPU architectures
|
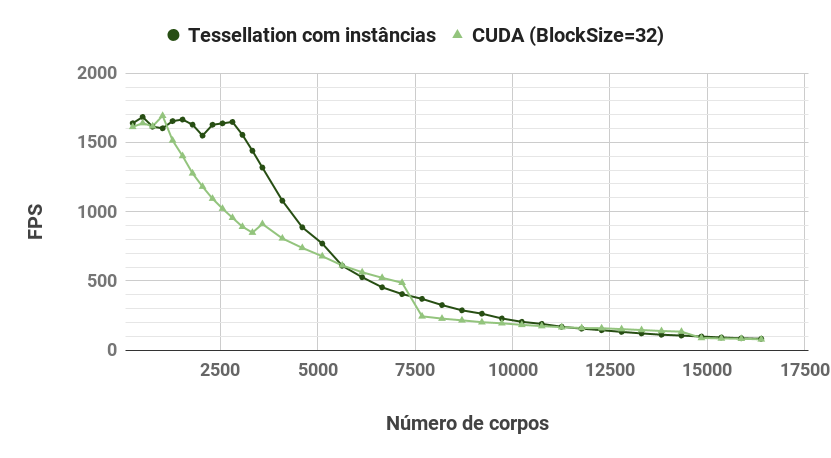
CUDA and tessellation+instancing comparison with block-size=32
|
The table below summarizes our findings, mapping the access to hardware features in CUDA and OpenGL.
Applying our contributions (rows 2 and 3) and that of Griffin et al.[1] (row 1) it is possible to obtain a better utilization of the hardware features exposed by the graphics pipeline.
Hardware Feature
|
Access in CUDA
|
Access in OpenGL
|
Reduce operations
|
Shared memory and atomic operations
|
Blending and render to texture
|
Block execution to group nearby data access and maximize memory bandwidth
|
Definition of block and grid dimensions at kernel execution call in source code
|
Instanced rendering
|
Shared memory
|
Use of __shared__ keyword when declaring kernel variables
|
Patch data during tessellation shader execution
|
Back to top
Papers
Accessing CUDA Features in the OpenGL Rendering Pipeline: A Case Study Using N-Body Simulation - full paper with poster presentation at SIBGRAPI2017 (pdf | poster)
Cloth Modeling with a Discrete Cosserat Surface - short paper (WIP thesis workshop) with poster presentation at SIBGRAPI2012 (pdf | poster)
Monographs
Estudo Comparativo entre OpenGL e CUDA em Acessos Aleatórios à Vizinhança de Primeira Ordem - master thesis monograph (pdf).
Um Estudo do Mapeamento de Estruturas BRep em GPU - qualifying monograph (pdf).
Back to top
Source code for both applications (curvature tensor estimator and gravitational n-body simulation), supporting Windows and Linux, is available at:
https://bitbucket.org/mariocamillo/mestrado
Back to top
Following previous works on the DeSMO project and concurrently with Mathias' work, this thesis began with the intention of analyzing the potential for improving the discrete Cosserat algorithm's performance with a GPU (Graphics Processing Unit) implementation.
As a first step the algorithm was profiled and the main bottleneck identified: the curvature tensor estimation.
This led to an initial translation of the curvature tensor estimation algorithm by Rusinkiewicz[4] to GPGPU (General Purpose GPU) that was implemented using OpenCL (Open Compute Language).
The figure below shows the data flow of the full discrete Cosserat algorithm and the parts implemented in GPU.
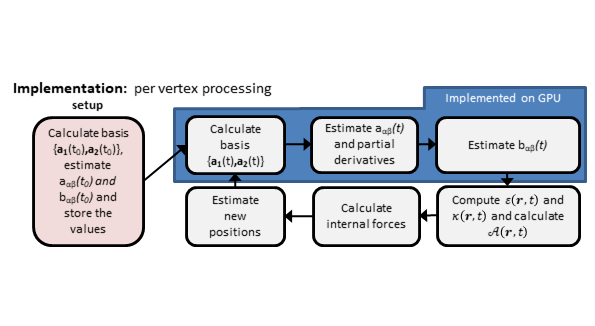
After this first implementation showed the gains of translating the algorithm to GPU we analyzed the bottleneck of the curvature tensor estimation algorithm, which is the accesses to the vertices and faces of the 1-ring neighborhood of a vertex.
Quick investigations determined that the non-coalesced nature of these accesses were not optimal for the GPU memory architecture and new and better data structures for the mesh were required to optimize the 1-ring neighborhood traversal.
The findings until then were presented in the qualifying monograph and in a conference poster in SIBGRAPI2012.
We conjectured that the tessellation shader, given its intrinsic need to access data of all vertices in a patch, would have hardware optimizations that would benefit 1-ring neighborhood accesses.
This was implemented in OpenGL (Open Graphics Library) and compared against an optimized implementation in CUDA (using shared memory) and an implementation in OpenGL of the algorithm proposed by Griffin et al.[1].
Unfortunately the results were not satisfactory and this led to a hiatus in the project.
After reading a paper by Niessner et al.[2] that explained the details of the tessellation shader and its implicit use of shared memory, and upon further questioning the black box nature of some of GPUs graphic pipeline optimizations and the prevalence of CUDA/OpenGL inter-operation instead of pure OpenGL implementations, we decided to restart the project with a new objective: compare and understand the optimizations available in CUDA and OpenGL for 1-ring neighborhood accesses.
This led to two new research activities.
First, a thorough re-analysis of the tensor curvature estimation problem, our implementations and the meaning of the results obtained.
And second, the selection of a new problem whose bottleneck was the 1-ring neighborhood accesses and which was normally implemented using CUDA/OpenGL inter-operation.
For this we identified another category of problems that are highly parallelizable and require 1-ring neighborhood access: n-body simulation.
The n-body simulation consists in the simulation of the interaction between n bodies and calculate their resulting position and speed at each iteration.
In the implementation of the gravitational n-body simulation we analyzed the optimized algorithm available in the NVidia CUDA SDK, written by Nyland et al.[3] and used different optimized hardware features exposed by OpenGL to attain the same performance as the OpenGL/CUDA inter-operation base implementation.
The features used include a direct application of Griffin et al.[1] use of the pixel blending, the tessellation shader and instanced rendering.
Our novel use of the tessellation shader and instanced rendering to reproduce the shared memory and synchronization use of the CUDA implementation was published as a conference paper on SIBGRAPI2017.
Finally our full comparative study between the use of OpenGL and CUDA for 1-ring neighborhood accesses, including both problems (curvature tensor estimation and n-body simulation) is described in Camillo's master thesis.
back to top
[1] - GRIFFIN, W.; WANG, Y.; BERRIOS, D.; OLANO, M. Real-time GPU surface curvature estimation on deforming meshes and volumetric data sets. IEEE transactions on visualization and computer graphics, v. 18, n. 10, p. 1603–13, out. 2012.
[2] - NIESSNER, M.; KEINERT, B.; FISHER, M.; STAMMINGER, M.; LOOP, C.; SCHÄFER, H. Real-time rendering techniques with hardware tessellation. Computer Graphics Forum, EG, 2015.
[3] - NYLAND, L.; HARRIS, M.; PRINS, J. Fast n-body simulation with cuda. In: NGUYEN, H. (Ed.). GPU Gems 3. [S.l.]: Addison-Wesley Professional, 2007. cap. 31.
[4] - RUSINKIEWICZ, S. Estimating curvatures and their derivatives on triangle meshes. In: Symposium on 3D Data Processing, Visualization, and Transmission. [S.l.: s.n.], 2004.
Back to top







